Autoregressive language models based on the decoder-only Transformer architecture generate tokens sequentially, conditioning each prediction on all previously generated tokens. During inference, the key-value pairs of prior tokens must be retained to ensure coherence across the generation sequence. In the standard Multi-Head Attention (MHA) formulation, the size of this KV cache grows linearly with both the sequence length and the number of attention heads, creating a significant memory bottleneck that limits the maximum context length achievable on commodity hardware. Multi-Head Latent Attention (MLA), introduced in DeepSeek-V2, addresses this bottleneck through low-rank joint projection of the key and value representations, achieving KV cache sizes comparable to Grouped-Query Attention (GQA) while preserving — and in some cases exceeding — the modeling capacity of full MHA.
This article presents a detailed analysis of the MLA mechanism, including its low-rank compression strategy, the decoupled Rotary Position Embedding (RoPE) design, and the weight-absorption trick that enables efficient inference. We also provide a rigorous comparison of the computational and memory costs of MLA relative to MHA, MQA, and GQA.
Notation
| Symbol | Description |
|---|---|
| Dimension of embedding per attention head | |
| KV compression dimension in MLA | |
| Query compression dimension in MLA | |
| Per-head dimension of the decoupled RoPE queries and keys in MLA | |
| Number of attention heads | |
| Number of KV groups in GQA | |
| Number of Transformer layers | |
| Attention input for the -th token at a given layer | |
| Output hidden state for the -th token at a given layer |
Background: KV Cache in Autoregressive Transformers
In a decoder-only Transformer, each autoregressive step processes the current token embedding through a series of projections to produce query, key, and value vectors for every attention head:
where are the projection weight matrices and denote the query, key, and value for head of token .
Within each head, the attention output is computed as a weighted sum over all prior values:
The final layer output is obtained by concatenating the per-head outputs and projecting:
To avoid redundant recomputation, the key-value pairs are cached after their first computation. The per-token KV cache size in MHA is therefore per layer, yielding a total cache of elements per token. For a model with , , and , this amounts to nearly one million float16 parameters per token — a substantial memory footprint that grows without bound as the sequence length increases.
Prior Approaches: MQA and GQA
Multi-Query Attention (MQA) [Shazeer, 2019] collapses all heads to share a single pair of key and value projections, reducing the per-token KV cache to . Although effective in reducing memory, the aggressive sharing of KV representations across heads degrades model quality, as each head loses its distinctive key-value subspace.
Grouped-Query Attention (GQA) [Ainslie et al., 2023] interpolates between MHA and MQA by partitioning the query heads into groups, each sharing one key-value head. The per-token KV cache becomes , where controls the trade-off between cache efficiency and model capacity. When , GQA reduces to MHA; when , it reduces to MQA.
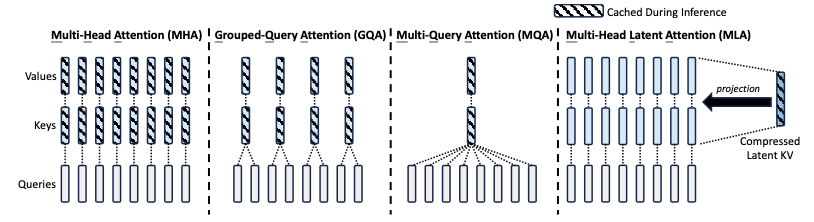
Complexity Comparison
It is instructive to compare the per-token KV cache and the per-layer FLOPs for each attention variant. For a sequence of length with hidden dimension :
| Method | KV Cache per Token (per layer) | Key Projection FLOPs | Value Projection FLOPs |
|---|---|---|---|
| MHA | |||
| GQA | |||
| MQA | |||
| MLA |
In MHA, the KV projection matrices require FLOPs per token, and the cache must store elements per layer. GQA reduces the projection cost to by sharing KV within each group, but the cache reduction is proportional to . MQA achieves the smallest projection cost of but at the cost of collapsing all head-specific information. MLA, by contrast, uses a single compressed vector of dimension from which both key and value are up-projected. The key and value projection costs are each , and the cache stores only elements (the compressed vector plus the decoupled RoPE key). Critically, the cache size is independent of , which allows MLA to increase the number of heads freely without any cache penalty — a property that none of the other methods possess.
Low-Rank Joint Key-Value Compression
The central innovation of MLA is the joint low-rank compression of the key and value representations. Rather than projecting independently into key and value spaces of dimension , MLA first projects it into a low-dimensional latent space and then up-projects separately to recover the key and value:
Here is the compressed latent vector, which is the only representation stored in the KV cache during inference. The down-projection matrix is , and the up-projection matrices are and . The compression dimension is chosen to be much smaller than ; in DeepSeek-V2, , which for yields , compared to for .
The low-rank structure imposes a bottleneck: the key and value vectors for all heads are constrained to lie in a -dimensional subspace. This is a form of information compression, and the key question is whether dimensions suffice to preserve the expressive power of the full-rank key and value. Empirically, DeepSeek-V2 demonstrates that with , MLA not only matches but slightly exceeds the performance of MHA — a result we revisit in the discussion of experimental results.
To further reduce the memory footprint during training (where the query activations must also be stored for backpropagation), MLA applies the same low-rank compression strategy to the query:
where is the compressed query latent, , and . Note that the query compression affects only training memory, not inference cache size, since queries are not cached.
Decoupled Rotary Position Embedding
Rotary Position Embedding (RoPE) [Su et al., 2024] encodes positional information by applying a rotation matrix to the query and key vectors. For a vector , the rotation at position is defined as:
where each is a 2D rotation by angle :
The key property of RoPE is that the attention score between a query at position and a key at position depends only on the relative position :
since by the group structure of rotation matrices.
The Incompatibility Problem
In MLA, the key is reconstructed from the compressed latent: . If one were to apply RoPE naively by rotating the reconstructed key, the result would be . Since is the cached quantity, this rotation must be applied at every inference step for all cached positions — defeating the purpose of caching. Moreover, the rotation matrix cannot be absorbed into because is position-dependent and varies across tokens; there is no fixed matrix that can be pre-multiplied into to account for all positions simultaneously.
Equivalently, consider attempting to absorb into . We would like to write:
but depends on the position , meaning it cannot be pre-computed and must be materialized for each token — incurring an cost per token, which is exactly the cost we sought to avoid.
The Decoupled Solution
DeepSeek-V2 resolves this by separating the positional and content components of the key. The content information is carried by the compressed latent (up-projected without RoPE), while the positional information is carried by a separate, small set of RoPE-encoded key vectors that are shared across all heads.
Query side. The compressed query latent is first up-projected and then RoPE is applied:
where produces a separate set of RoPE queries of dimension per head. The final query for head is the concatenation of the content and positional parts:
Key side. The content key is up-projected from the compressed latent without RoPE:
and the positional key is produced from the raw hidden state with RoPE:
where and the resulting is shared across all heads. The final key for head is:
This decoupling ensures that the compressed latent is stored as-is in the cache (without any position-dependent transformation), while the position information is captured by the small additional vector of dimension .
Attention Score Computation
With the decoupled query and key, the attention score for head decomposes into a content component and a positional component:
The attention output is then:
The per-token cache now stores and , for a total of elements per layer — independent of .
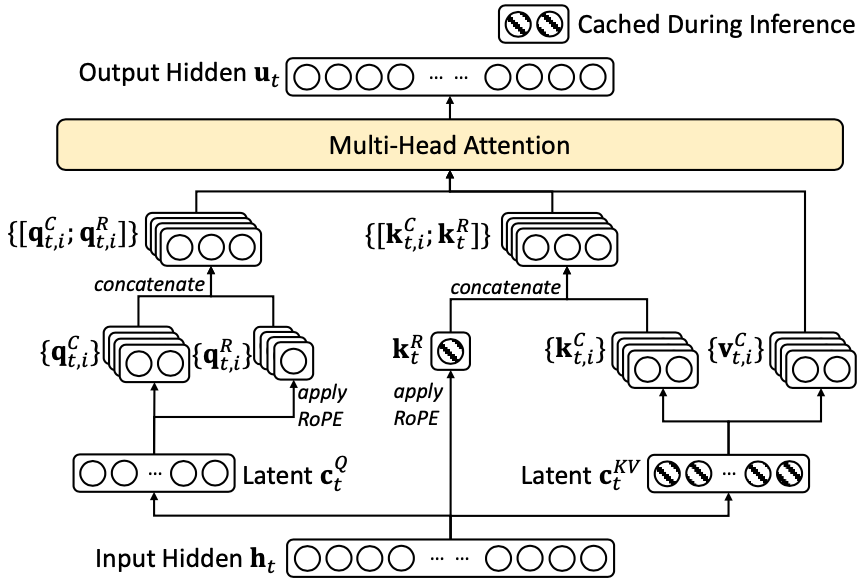
Inference-Time Weight Absorption
A crucial advantage of MLA is that the up-projection matrices and can be absorbed into other weight matrices at inference time, effectively eliminating the cost of explicitly reconstructing the full key and value vectors.
Key Absorption: into
Consider the content term of the attention score:
where and respectively are the slices of the up-projection matrices corresponding to head . The product can be pre-computed once and reused for all tokens, since it depends only on the model weights, not on the input. Let us define:
Then the content attention score simplifies to:
This means the attention score is computed directly from the compressed representations and , without ever materializing the full -dimensional key or query vectors. The pre-computed matrix has size , which is small compared to the original key projection .
Value Absorption: into
After computing the attention weights, the weighted sum of values is:
where are the attention weights for head and is the value up-projection for head . Since the weighted sum is a vector in , the computation proceeds as:
- Compute the weighted sum in the compressed space: .
- Up-project: .
Now, the final output projection concatenates all heads and applies :
This can be rewritten by merging and into a single matrix. Let where . Then:
where can be pre-computed. The net effect is that the value up-projection and output projection are fused into a single matrix multiplication per head, and the full -dimensional value vectors never need to be materialized.
Summary of Absorption Benefits
| Quantity | Without Absorption | With Absorption |
|---|---|---|
| Cached per token | (full KV) | (compressed) |
| Key score FLOPs per query–key pair | (dot product in ) | (per head, via ) |
| Value aggregation | per head | per head (sum in compressed space) |
| Output projection | per head (via ) |
The absorption trick transforms MLA from a method that merely compresses the cache into one that also reduces the computational cost of the attention operation itself.
Experimental Results
The following table summarizes the per-token KV cache comparison across methods, using the DeepSeek-V2 configuration where and :
| Method | KV Cache per Token (per layer) | Relative Size |
|---|---|---|
| MHA | (baseline) | |
| GQA | ||
| MQA | ||
| MLA |
For and , MHA requires elements per layer per token, while MLA requires only — a compression ratio of approximately .
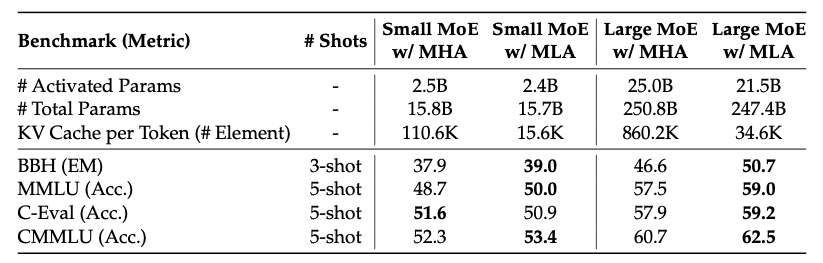
The benchmark results demonstrate that MLA not only matches but slightly exceeds MHA across a range of evaluation metrics. This may appear counterintuitive for a compression-based method, but the explanation lies in the architectural flexibility afforded by the independence of the KV cache from the head count. In standard MHA, increasing the number of heads linearly increases the KV cache, creating a hard constraint on model width. In MLA, the KV cache size depends only on and , so the number of heads can be increased freely to enhance model capacity without any cache penalty. DeepSeek-V2 exploits this by using approximately the typical head count, distributing the same total hidden dimension across more heads with smaller per-head dimensions. The resulting model has finer-grained attention patterns while maintaining an efficient cache footprint.
References
DeepSeek-AI. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” arXiv preprint arXiv:2405.04434, 2024.
Shazeer, N. “Fast Transformer Decoding: One Write-Head is All You Need.” arXiv preprint arXiv:1911.02150, 2019.
Ainslie, J., Lemercier, P., et al. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” Proceedings of EMNLP, 2023.
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., and Liu, Y. “RoFormer: Enhanced Transformer with Rotary Position Embedding.” Neurocomputing, 2024.